Research
Era of Experience – How David Silver Is Reimagining the World of AI Once Again
21 March 2026 · reinforcement learning · world models · experience learning · decision intelligence
David Silver is the man behind AlphaGo, AlphaZero and MuZero. Three systems that showed how far Reinforcement Learning can go when you actually let it. Now Silver has left DeepMind to found his own company, Ineffable Intelligence. The seed round is reported to be around one billion dollars, the largest ever raised by a European startup. But what is the idea behind it? Silver and his longtime colleague Richard Sutton, one of the founding fathers of modern Reinforcement Learning, have laid out their vision in a concise paper: “Welcome to the Era of Experience”.
The problem with today’s AI systems
Large language models like ChatGPT or Gemini are impressive. They write, translate, explain, at a level that would have seemed impossible just a few years ago. But they share a fundamental limitation: they learn from human knowledge that already exists. Silver and Sutton put it directly. The best data sources have largely been consumed. Progress through scaling training data is measurably slowing down. And new insights, real breakthroughs in mathematics, science and technology, cannot simply be scraped from the internet. They still need to be discovered. The answer? Learning from experience instead of from text.
The three core ideas of the paper
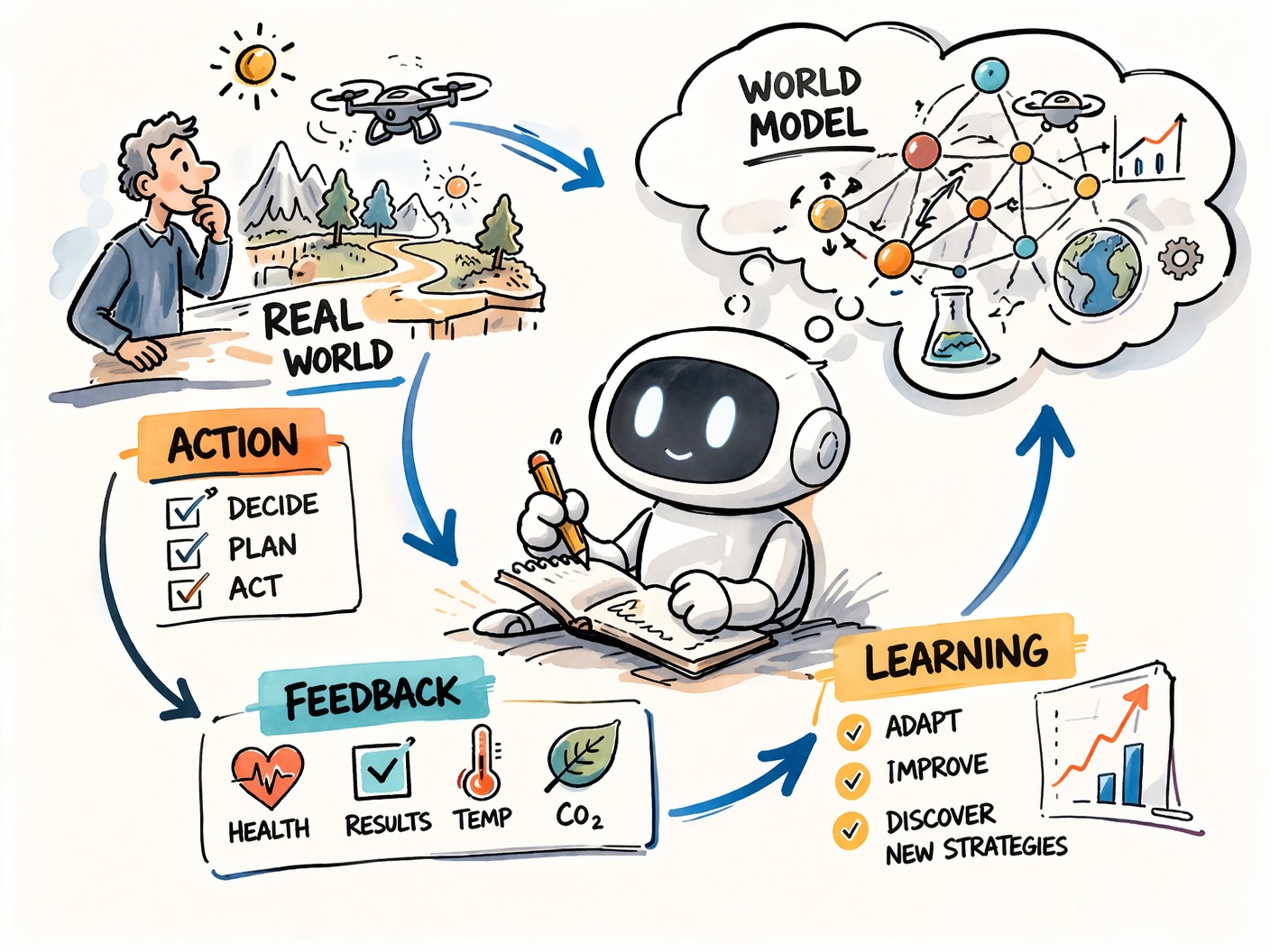
Streams instead of episodes
Today’s AI systems operate in short interactions. Question in, answer out, done. No memory, no adaptation over time. Silver and Sutton argue that powerful agents need to exist in a continuous stream of experience, like humans do, learning, self-correcting and adapting to their environment over months and years. That sounds abstract, but the implications are concrete. A health assistant that tracks your sleep patterns over months and continuously refines its recommendations. A science agent that independently plans experiments, evaluates results and develops new hypotheses.
Grounded rewards instead of human judgment
Current AI systems are trained on human feedback. An expert evaluates whether a response was good. The problem is that this judgment is based on human preconceptions, not on the actual consequences of the action.
Silver and Sutton propose grounded rewards instead: signals that come directly from the world. Heart rate instead of expert opinion. Exam results instead of a teacher’s assessment. CO₂ measurements instead of an environmental consultant’s feedback.
This is not a small shift. It means an agent experiences the real consequences of its decisions and learns from them. That is exactly what made RL so powerful in games: clear, unbiased signals.
World models as a thinking tool
For me as an RL practitioner, this is the most exciting building block: World Models. Instead of learning directly from every experience, the agent builds an internal model of how the world works, and can use it to plan in imagination before acting in reality. Think of the difference between a student who blindly solves problems and one who actually understands why a solution works. World models allow an agent to predict consequences without having to test them in the real world. For expensive or high-stakes systems, autonomous drones being a good example, this is not a nice-to-have. It is a prerequisite.
From AlphaProof to the Era of Experience
Silver illustrates his argument with a concrete example. AlphaProof, DeepMind’s system for mathematical proofs, started with around one hundred thousand proofs created by human mathematicians. From there, the RL system generated one hundred million more through direct interaction with a formal proof environment, and reached International Mathematical Olympiad medal level in the process. That is the principle in action. A small foundation of human knowledge, followed by autonomous learning that goes far beyond any human ceiling.
What this means for my work
For me as an RL engineer, this paper is not abstract theory. I work on systems that help dispatchers assign tasks to available work teams. Today, that model is trained on rewards defined by domain experts, essentially someone’s best guess of what “good” looks like.
The Era of Experience points at something more powerful: a model that learns from direct, unfiltered feedback. Not what an expert thinks should happen, but what actually happens when a decision is made. Over time, such a system could suggest assignments that look noting like what any dispatcher would have tried, and that is exactly the point. It generates genuinely new knowledge, not just better versions of existing patterns.
At the same time, the human stays in the loop. When a dispatcher overrides the system based on intuition or context the model cannot see, that override becomes part of the experience. The system learns from it. That is the feedback loop Silver and Sutton describe, and it is the one I find most relevant for real-world deployment.
Conclusion
Silver and Sutton do not deliver a finished system with Era of Experience. They deliver an agenda. A clear argument for why the next major step in AI will not come from more training data, but from agents that have real experiences, face real consequences and learn from them continuously. Silver has stated the goal of his new company plainly: to build an endlessly learning superintelligence that discovers the foundations of all knowledge by itself. Whether that succeeds remains to be seen. But the direction is right, and it is more interesting than the tenth GPT clone.
Paper: Silver, D. & Sutton, R.S. “Welcome to the Era of Experience” (MIT Press, forthcoming in: Designing an Intelligence)